"Why kaggle datasets are not reliable"
A story about data analysis
Hello Everyone ! excited to write my first story haha.
Down below we have small dataset from kaggle. AI impact on jobs by 2030
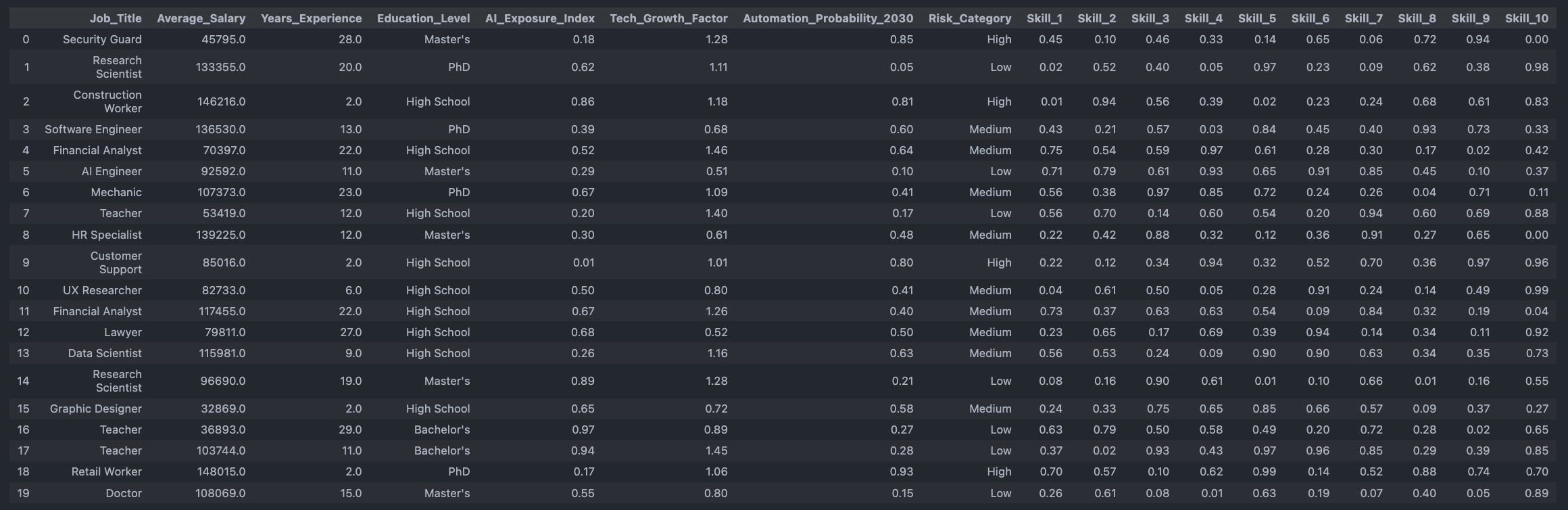
Goal of this story was to demonstrate reliability risks using internal consistency check with distribution diagnosis.
First of all : There is no documented data source ( prediction model ) or sampling frame. No uncertainty estimates , hence external validity can't be established.
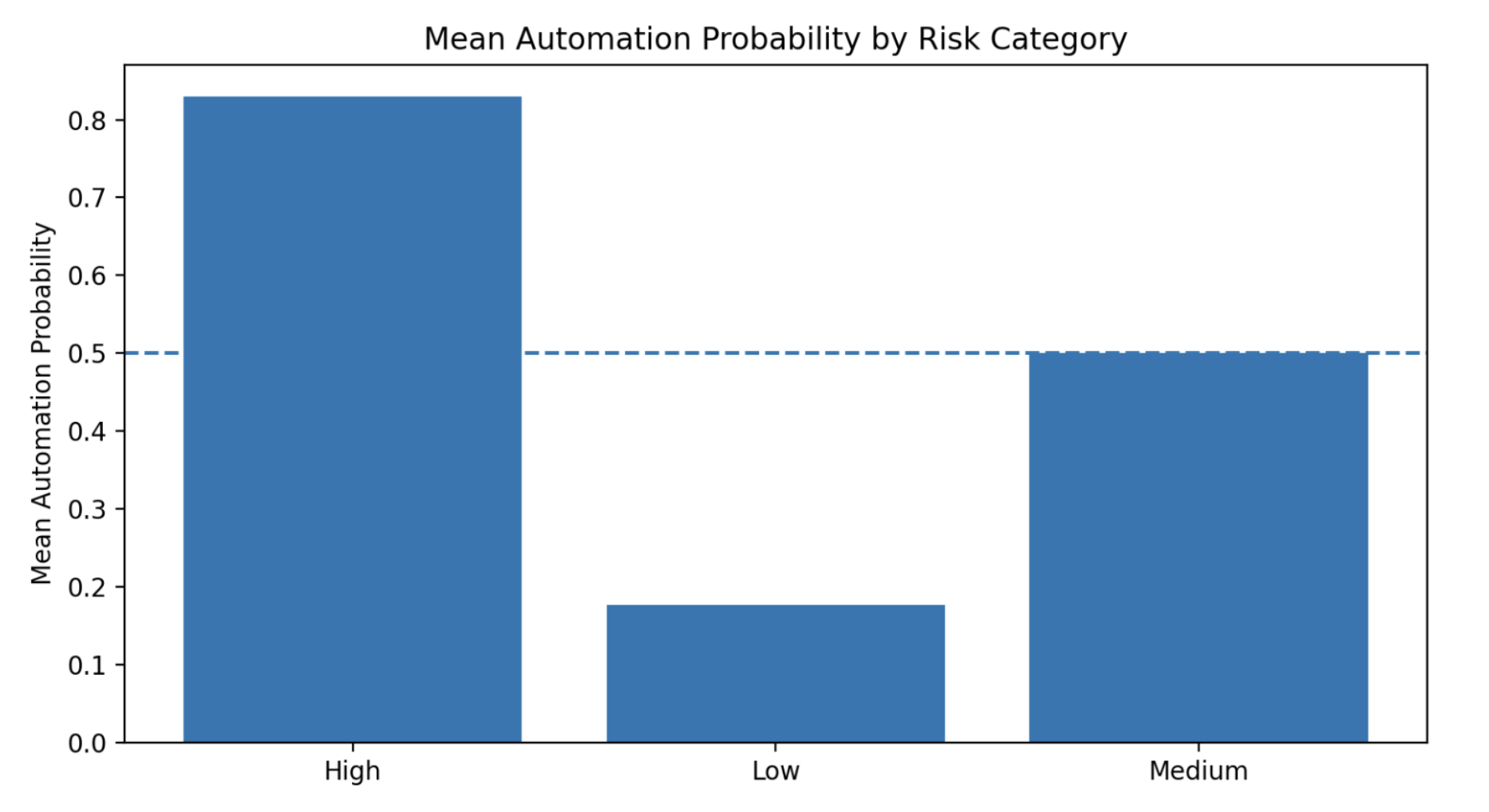
From the data set low risk jobs with >70% automation probability = 0. P.s hopefully it turns out to be wrong prediction.
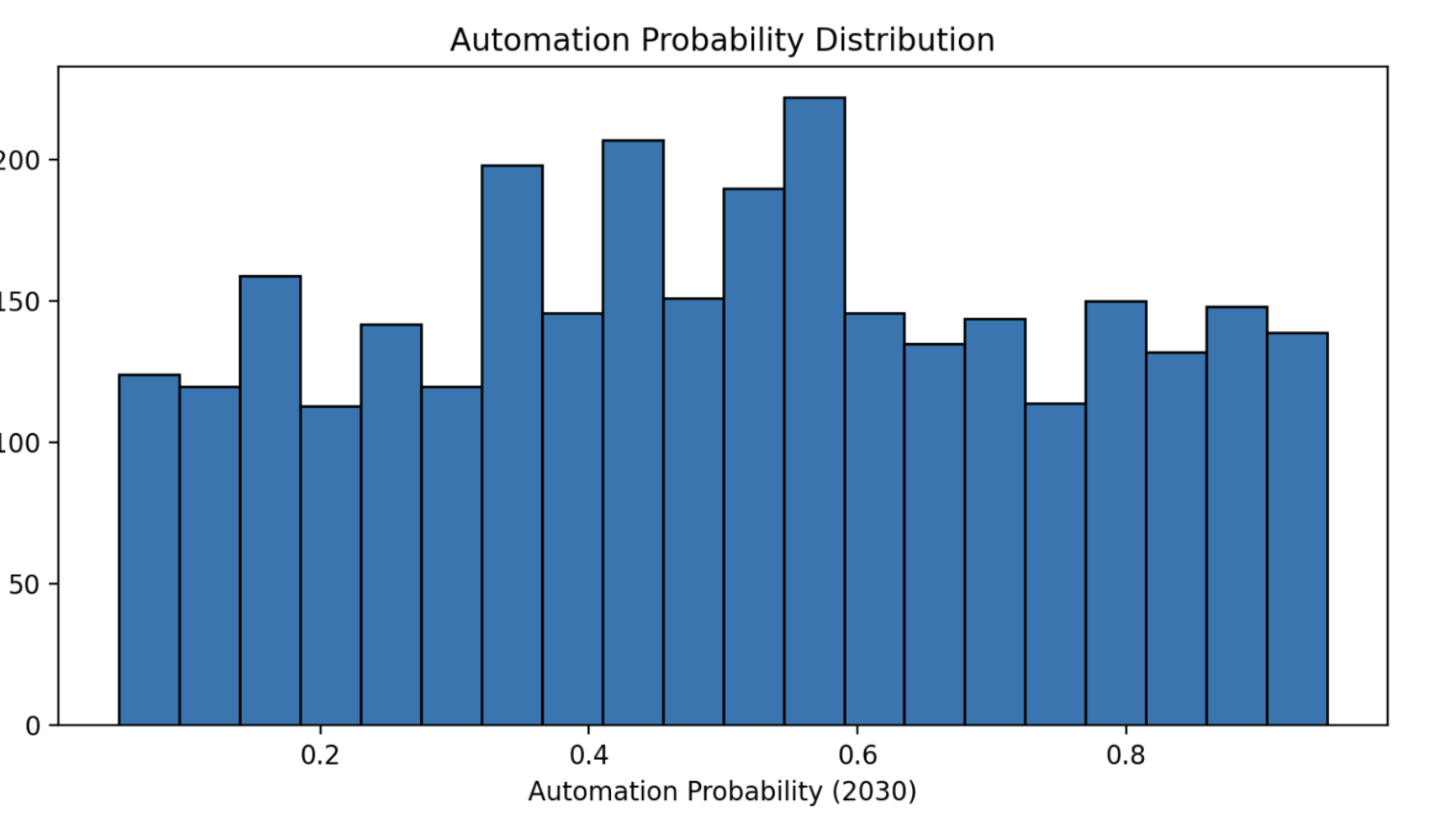
typically real datasets show heavier skew , more outliers and noise ( since it's real data )

Phd entries earning less than 60k usd per year =203 rows.
To conclude : Kaggle ≠ Ground Truth
This dataset looks realistic, but:
variables contradict each other
distributions lack real-world noise
labels are not derivable from underlying data